## ------------------------------------------------------------
## classification
## ------------------------------------------------------------
## -------- iris data
## iris "Petal.Width" partial dependence plot
##
# rfsrc_iris <- rfsrc(Species ~., data = iris)
# partial_iris <- plot.variable(rfsrc_iris, xvar.names = "Petal.Width",
# partial=TRUE)
data(partial_iris, package="ggRandomForests")
gg_dta <- gg_partial(partial_iris)
plot(gg_dta)## [[1]]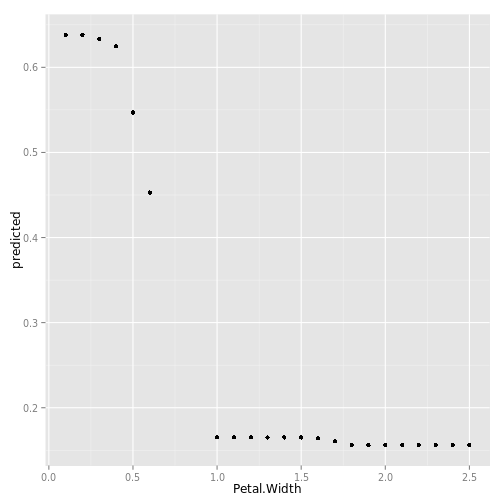
##
## [[2]]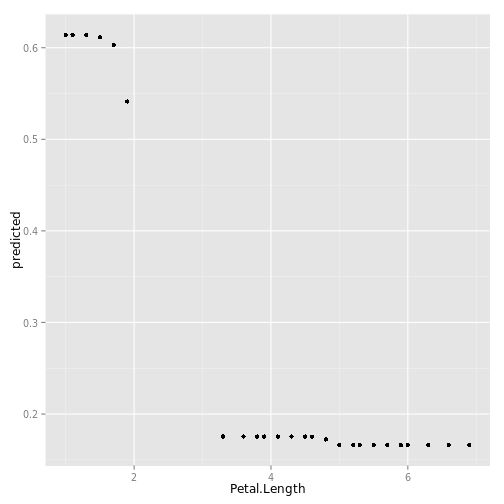
##
## [[3]]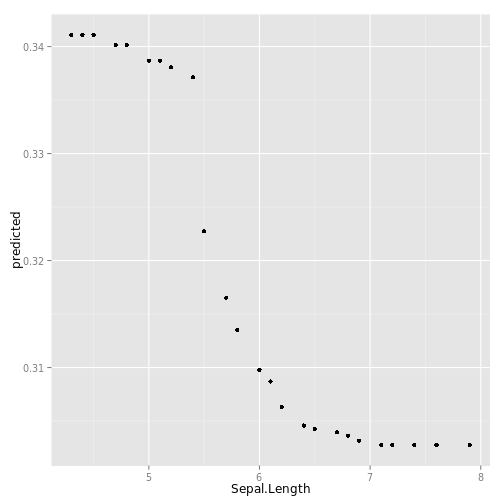
##
## [[4]]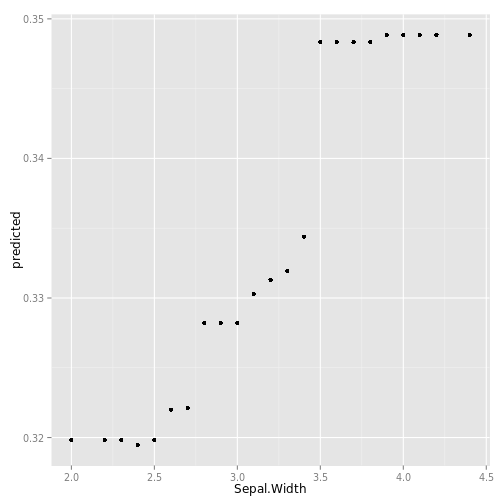
## ------------------------------------------------------------
## regression
## ------------------------------------------------------------
## Not run:
##D ## -------- air quality data
##D ## airquality "Wind" partial dependence plot
##D ##
##D # rfsrc_airq <- rfsrc(Ozone ~ ., data = airquality)
##D # partial_airq <- plot.variable(rfsrc_airq, xvar.names = "Wind",
##D # partial=TRUE, show.plot=FALSE)
##D data(partial_airq, package="ggRandomForests")
##D
##D gg_dta <- gg_partial(partial_airq)
##D plot(gg_dta)
##D
##D gg_dta.m <- gg_dta[["Month"]]
##D plot(gg_dta.m, notch=TRUE)
##D
##D gg_dta[["Month"]] <- NULL
##D plot(gg_dta, panel=TRUE)
## End(Not run)
## -------- Boston data
data(partial_Boston, package="ggRandomForests")
gg_dta <- gg_partial(partial_Boston)
plot(gg_dta, panel=TRUE)## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.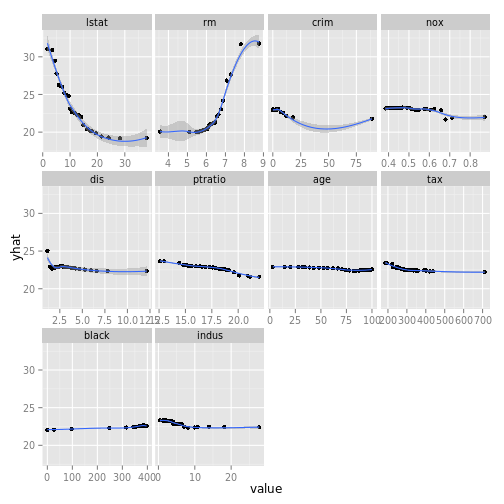
## Not run:
##D ## -------- mtcars data
##D data(partial_mtcars, package="ggRandomForests")
##D gg_dta <- gg_partial(partial_mtcars)
##D
##D gg_dta.cat <- gg_dta
##D gg_dta.cat[["disp"]] <- gg_dta.cat[["wt"]] <- gg_dta.cat[["hp"]] <- NULL
##D gg_dta.cat[["drat"]] <- gg_dta.cat[["carb"]] <- gg_dta.cat[["qsec"]] <- NULL
##D
##D plot(gg_dta.cat, panel=TRUE, notch=TRUE)
##D
##D gg_dta[["cyl"]] <- gg_dta[["vs"]] <- gg_dta[["am"]] <- NULL
##D gg_dta[["gear"]] <- NULL
##D plot(gg_dta, panel=TRUE)
## End(Not run)
## ------------------------------------------------------------
## survival examples
## ------------------------------------------------------------
## Not run:
##D ## -------- veteran data
##D ## survival "age" partial variable dependence plot
##D ##
##D # data(veteran, package = "randomForestSRC")
##D # rfsrc_veteran <- rfsrc(Surv(time,status)~., veteran, nsplit = 10, ntree = 100)
##D #
##D ## 30 day partial plot for age
##D # partial_veteran <- plot.variable(rfsrc_veteran, surv.type = "surv",
##D # partial = TRUE, time=30,
##D # xvar.names = "age",
##D # show.plots=FALSE)
##D data(partial_veteran, package="ggRandomForests")
##D
##D gg_dta <- gg_partial(partial_veteran[[1]])
##D plot(gg_dta)
##D
##D gg_dta.cat <- gg_dta
##D gg_dta[["celltype"]] <- gg_dta[["trt"]] <- gg_dta[["prior"]] <- NULL
##D plot(gg_dta, panel=TRUE)
##D
##D gg_dta.cat[["karno"]] <- gg_dta.cat[["diagtime"]] <- gg_dta.cat[["age"]] <- NULL
##D plot(gg_dta.cat, panel=TRUE, notch=TRUE)
##D
##D gg_dta <- lapply(partial_veteran, gg_partial)
##D gg_dta <- combine.gg_partial(gg_dta[[1]], gg_dta[[2]] )
##D
##D plot(gg_dta[["karno"]])
##D plot(gg_dta[["celltype"]])
##D
##D gg_dta.cat <- gg_dta
##D gg_dta[["celltype"]] <- gg_dta[["trt"]] <- gg_dta[["prior"]] <- NULL
##D plot(gg_dta, panel=TRUE)
##D
##D gg_dta.cat[["karno"]] <- gg_dta.cat[["diagtime"]] <- gg_dta.cat[["age"]] <- NULL
##D plot(gg_dta.cat, panel=TRUE, notch=TRUE)
## End(Not run)
## -------- pbc data
data("partial_pbc", package = "ggRandomForests")
data("varsel_pbc", package = "ggRandomForests")
xvar <- varsel_pbc$topvars
# Convert all partial plots to gg_partial objects
gg_dta <- lapply(partial_pbc, gg_partial)
# Combine the objects to get multiple time curves
# along variables on a single figure.
pbc_ggpart <- combine.gg_partial(gg_dta[[1]], gg_dta[[2]],
lbls = c("1 Year", "3 Years"))
# Plot the highest ranked variable, by name.
plot(pbc_ggpart[["bili"]], se = FALSE)## Warning: The plyr::rename operation has created duplicates for the
## following name(s): (`se`)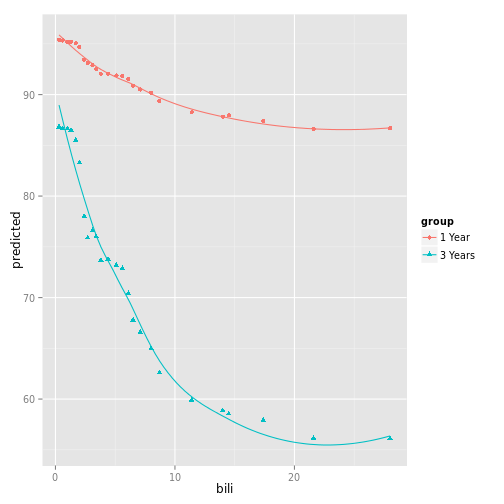
# Create a temporary holder and remove the stage and edema data
ggpart <- pbc_ggpart
ggpart$edema <- NULL
# Panel plot the remainder.
plot(ggpart, se = FALSE, panel = TRUE)## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.
## geom_smooth: method="auto" and size of largest group is <1000, so using loess. Use 'method = x' to change the smoothing method.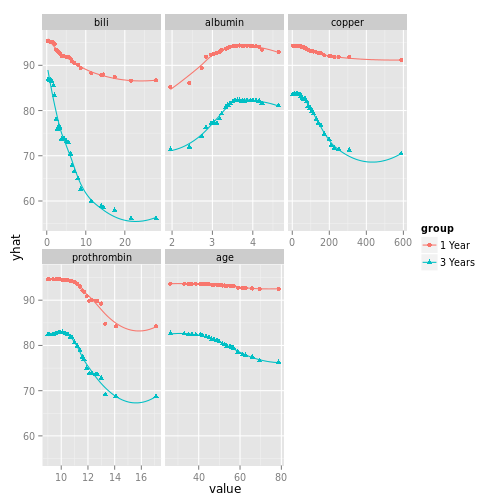
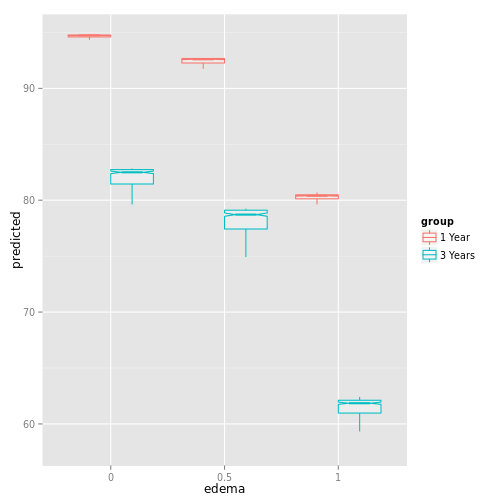
plot(pbc_ggpart[["edema"]], panel=TRUE,
notch = TRUE, alpha = .3, outlier.shape = NA)## Warning: Removed 50 rows containing missing values (geom_point).## Warning: Removed 39 rows containing missing values (geom_point).## Warning: Removed 35 rows containing missing values (geom_point).## Warning: Removed 14 rows containing missing values (geom_point).## Warning: Removed 32 rows containing missing values (geom_point).## Warning: Removed 23 rows containing missing values (geom_point).